AppCache's forgotten tales
The beginning of this story is almost as old as Chrome itself. It started ten years ago - precisely on version 5.0.375 - when Application Cache (AppCache) was first implemented and shipped into Chrome.
Its three main purposes were to provide:
- Offline browsing - allowing users to navigate to websites even when offline.
- Speed - loading resources straight from the disk, with no trip to the network.
- Resilience - providing an offline experience even if a website went down for “maintenance”.
Over time, as the web grew and evolved, AppCache lost its relevance with the rising popularity of new features such as Service Workers and ended relegated to the sidelines of web application development.
More than that - Chrome’s AppCache implementation proved to be a security and stability liability - becoming the 2nd most troublesome client-side storage API in the Web Platform [1], with over 400 Chromium CLs during the period of 2018 and 2019.
It was no surprise when Application Cache was both deprecated and set under removal in WHATWG’s standard [2] as well as marked obsolete in W3C’s HTML 5.1 [3].
The Chrome team followed suit by deprecating AppCache in Chrome 67 as part of a larger effort to remove powerful features on insecure origins [4] - it was soon removed from non-secure contexts [5] in Chrome 70.
This culminated in the decision to remove AppCache once and for all, and although it was scheduled to happen in Chrome 82 [6] it ended being postponed to Chrome 85 [7].
Chrome’s AppCache was finally removed by default in Chrome 85, yet there remained a small caveat: websites that didn’t make the transition in time could opt-in into a “reverse” origin trial [8] and re-enable it on secure contexts - its last, dying breath.
The definitive removal (with completion of the origin trial) is set to happen in Chrome 93 (estimated to be around October 2021).
Saying goodbye
Having learned of AppCache’s death announcement and being aware of its problematic past, I decided this would be a great opportunity to look for bugs before it plunged into eternal slumber. I was curious whether there remained any unexplored issues this far into the feature’s life cycle.
With a general understanding of how the Application Cache worked and armed with the knowledge of great past research by @filedescriptor [9] and Frans Rosén (@fransrosen) [10] (where both independently discovered ways to exploit sandbox domains through the use of the AppCache) I had a vague notion of where to look and where not to.
Since I was interested in attacks that worked cross-origin (given their wider implications) I discarded the FALLBACK and the CHROMIUM-INTERCEPT sections as possible vectors since they only take same-origin URLs as entries.

A small addendum - you may have noticed that the CHROMIUM-INTERCEPT section is not listed above nor appears in the HTML standard.
That’s the case because Chrome decided to deviate from the standard and implemented a new feature with its own set of rules.
Although it won’t factor in this article, you can get more information about them by reading Jun Kokatsu (@shhnjk)’s “Intro to Chrome’s (g)old features” blog post [11] as well as the report tracking the feature’s implementation [12].
Cache section
From experimenting with the Cache section in a previous research related to XSLeaks, I learned that it could be leveraged to detect whether a cross-origin request resulted in a redirect or not - it felt natural to use this discovery as a starting point and try to expand on it.
I started by setting a cache manifest and an HTML page in the following way:
CACHE MANIFEST
https://www.facebook.com/settings
<html manifest="manifest.appcache">
<script>
applicationCache.onerror = () => console.log("User isn't logged since there was a redirect");
applicationCache.oncached = () => console.log("User is logged since there wasn't a redirect");
</script>
</html>
Since the /settings endpoint on Facebook can only be accessed by a logged user (a redirect to /login.php happens otherwise) we can leverage the error and cached events as oracles to detect whether a redirect happened or not, leaking information about the current status of the user.
This is made possible because the Application Cache is not able to cache entries that result in a redirect, for reasons described in the WHATWG’s standard [13].

Although the trick above is neat, it has two limitations that I couldn’t overcome using the Cache section alone:
- The endpoint has to conditionally issue a redirect depending on the state of the web application.
- Only one bit of information is leaked.
These restrictions are best exemplified by using a real-case scenario such as the one presented by the https://www.facebook.com/me endpoint.
- When the user is not logged a redirect to / is made.
- When the user is logged a redirect to /victim is made (the user’s profile page).
Our current oracle can only ask the question: “Did a redirect happen?" and given the lack of granularity, it is not able to distinguish between two redirects (as the error event would be triggered on both cases).
After trying different approaches and not going anywhere further, it was time to move on.
Network section
This was uncharted territory to me - up until this point I had never used the Network section and only had a vague notion of how it worked.
From reading the MDN documentation [14], my understanding was that resources listed in it would always be retrieved from the network and never from the cache. Likewise, resources not listed would be retrieved first from the cache, and if not found, from the network.
To be sure of how it worked, I continued my tests by adding a Network section to the manifest and included the /settings endpoint as an entry for it.
CACHE MANIFEST
NETWORK:
https://www.facebook.com/settings
The HTML file was then changed to make a fetch to said endpoint.
<html manifest="cache.manifest">
<script>
applicationCache.oncached = () => {
fetch("https://www.facebook.com/settings", { mode: "no-cors", credentials: "include" });
}
</script>
</html>
After accessing the page, nothing out of the ordinary happened. The fetch was performed as expected - without any redirects since I was logged on Facebook.

But something surprising happened when I decided to log out of Facebook and access the page again.
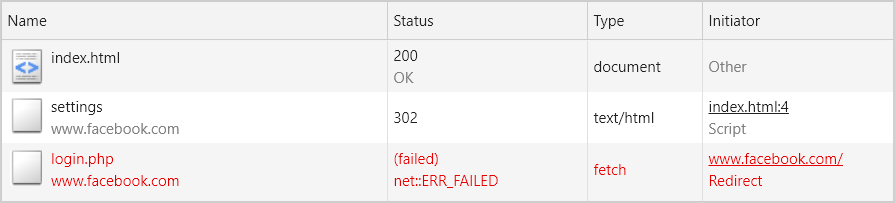
The redirect to /login.php was expected given I was logged out, but the subsequent request to it failed.
After trying to understand what had happened, I figured out I had a misconception about the way the Network section worked.
If you have a Network section set in your manifest and you try to request a URL that is neither an entry in your Network or Cache sections, the request will be rejected, effectively working as an allowlist. Even more interesting is that it also applies to requests originated from a redirect - as was seen above.
With that in mind, I added the /login.php endpoint as an entry to the Network section and accessed the page again while still being logged out - which resulted in the request finishing successfully without being blocked.
A new oracle is born
This discovery was fundamental to improve the attack’s granularity - it gave me the ability to confirm whether any given URL was part of a redirect or not, opening up a lot of possibilities.
To put that to the test I created the following manifest.
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/victim
As well as the following HTML file.
<html manifest="cache.manifest">
<script>
applicationCache.oncached = () => {
fetch("https://www.facebook.com/me", {
mode: "no-cors",
credentials: "include"
}).then(() => {
console.log("The profile of the user is /victim");
}).catch(()= > {
console.log("The profile of the user isn't /victim");
});
}
</script>
</html>
The idea behind the attack above is to use the allowlist-like properties of the Network section combined with the convenient way (catch) of detecting network errors of the Fetch API to leak even more information (in this instance to deanonymize the user).
The flow can be described by the following steps:
- A user navigates to a malicious page.
- The manifest is installed - which blocks all network connections except to /me and /victim.
- As soon as the manifest finishes being installed, a fetch is issued to /me.
- Since /me is an allowlisted entry in the Network section the request is allowed.
- Given the user is logged on Facebook, a redirect will be made to /victim (user’s profile page).
- If the username of the user is “victim”, the promise will finish normally because /victim is an allowlisted entry in the Network section.
- If the username of the user is not “victim”, the promise will be rejected due to a network error caused by the non-existence of an entry matching that username.
A clear downside of this attack is that we would need to create a manifest with different usernames and issue a fetch to /me until we got a match, and this would take a lot of time.
Fortunately it is possible to speed up this process by creating a manifest like the one below - containing hundreds of thousands of usernames at the same time - and upon getting a match, doing a binary search to find the one that triggered it.
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/victim1
https://www.facebook.com/victim2
https://www.facebook.com/victim3
[...]
https://www.facebook.com/victim99998
https://www.facebook.com/victim99999
https://www.facebook.com/victim100000
It is a decent improvement, but would still require a very big wordlist of usernames and some luck…
Digging deeper
I was still curious about the inner workings of the Network section and decided to read Chrome’s AppCache implementation source code [15] - there I noticed telling keywords such as “URL patterns” and “not standardized” which caught my attention.

There were a lot of references about a non-standard feature involving patterns that I hadn’t come across yet. After a quick search, I found issue 224426 [16], which tracked the implementation of this particular feature.
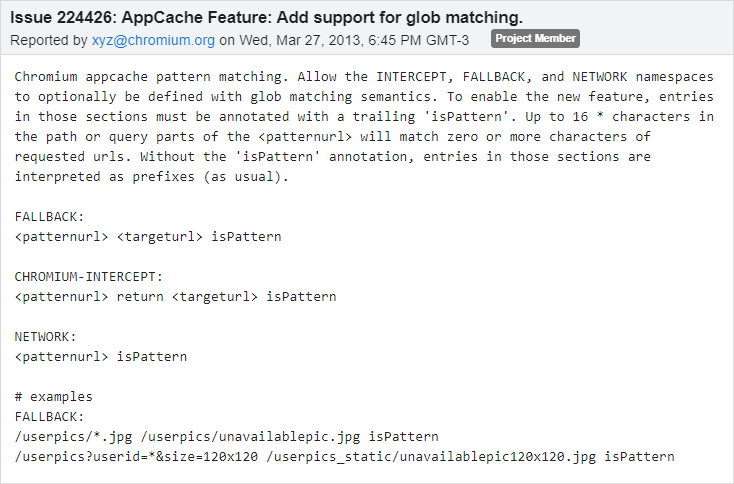
From reading the issue tracker I learned that around early 2013, support for pattern matching was added to the FALLBACK, INTERCEPT, and NETWORK sections of Chrome’s Application Cache.
From that point forward, URLs from those sections could be matched using glob semantics provided that the entries ended with a trailing “isPattern”.
A quick test proved that to be true - both manifests allowed network connections to the /me and /victim endpoints.
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/victim
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/vi*tim isPattern
(G)old features for the win
In the context of oracles, the ability to do pattern matching is a powerful tool - by leveraging the allowlist-like behavior of the Network section combined with the non-standard pattern matching feature, it became possible to brute-force (char-by-char) the URLs that were part of a cross-origin redirect chain.
The newly revised vector could then be summarized by the following steps:
- A manifest is created containing a Network section.
- The targeted endpoint that initiates the redirect is added as an entry to the Network section.
- Another entry is added to the Network section containing a base URL followed by a single random character (the trailing wildcard character and the “isPattern” must be included at the end of the entry).
- A request is made to the targeted endpoint and the attacker checks whether it resulted in a network error or not.
- If the request results in a network error, it means that the chosen character isn’t part of the URL in the targeted redirect chain.
Considering the previous scenario, a request made to the /me endpoint, governed by the rules established by the manifest below, would result in a network error (because the user is logged into the"victim” account).
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/a* isPattern
On the other hand, if a request was made under the rules of the following manifest, the request would be successful and the attacker would be able to infer that the first character of the victim’s username is “v”.
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/v* isPattern
We are not limited to one character-check per registered manifest, thus it is possible to improve the efficiency of the technique through the use of a binary search.
This happens by creating a single manifest comprising of entries in the Network section that match half of the possible characters that can appear in the URL of the targeted endpoint.
Supposing that a hypothetical charset is limited to the [a-z] characters - one would split them in half and create a malicious manifest using characters from “a” to “m” (half of the characters of the charset).
CACHE MANIFEST
NETWORK:
https://www.facebook.com/me
https://www.facebook.com/a* isPattern
https://www.facebook.com/b* isPattern
https://www.facebook.com/c* isPattern
[...]
https://www.facebook.com/g* isPattern
[...]
https://www.facebook.com/k* isPattern
https://www.facebook.com/l* isPattern
https://www.facebook.com/m* isPattern
If the manifest above was registered and a request made to the /me endpoint, there would be two possible outcomes:
- The request would return successfully, allowing the attacker to infer that the first character of the victim’s username is in the [a-m] range.
- The request would result in a network error, allowing the attacker to infer that the first character is in the [n-z] range.
This process is repeated several times, each iteration narrowing the possible characters by half until only one is left - thus leaking the first letter of the victim’s username.
The subsequent characters could also be leaked by the same process - with each character found being appended to the end of the targeted URL used in the cache manifest.
Hands-on
I reported my findings to Google by filling report 1039869 [17] through the Chrome VRP [18], and they fixed it promptly (within the span of seven days).
In the meantime, I began to think about scenarios where the leak of complete URLs of cross-origin redirects would be impactful:
- Redirects to URLs that contain a session token in the query string.
- Redirects to URLs that contain a CSRF token in the query string.
- Redirects to sensitive information (private documents, photos, etc).
- Redirects to the user’s profile (for deanonymization).
With them in mind, I looked for a real-world case to confirm that exploitability in the wild was possible - and funnily enough, I didn’t even need to get out of Chrome’s issue tracker website.
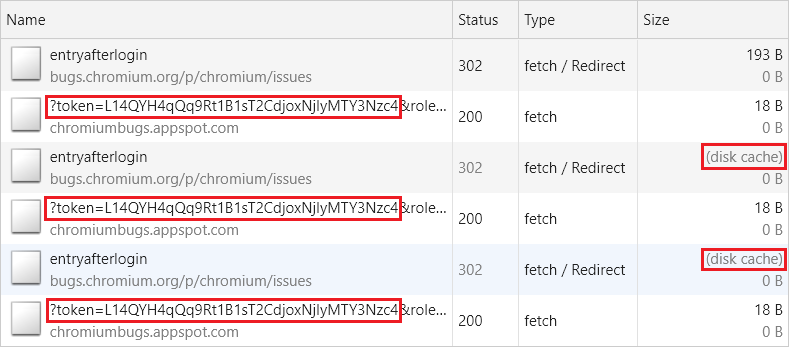
I stumbled upon the https://bugs.chromium.org/p/chromium/issues/entryafterlogin endpoint, which is used to redirect users to the “report form” after they authenticate.
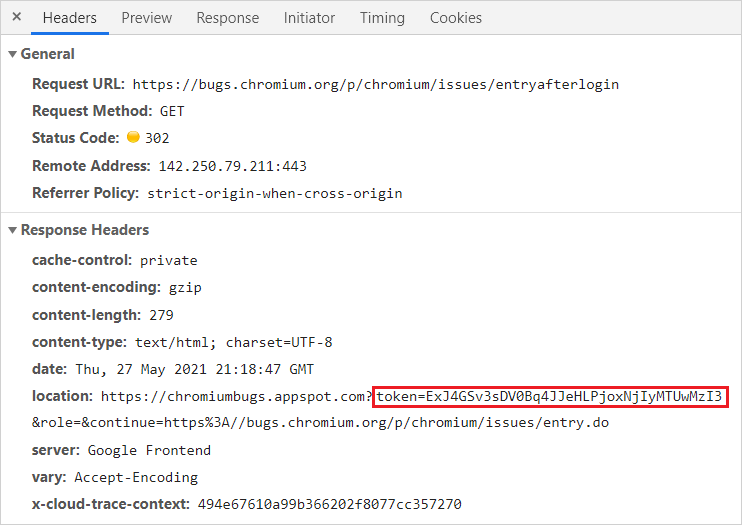
Conveniently, the endpoint was redirecting to a page that contained a CSRF token in the query string, as it can be seen above - fulfilling one of the requisites to pull the attack off!
A request to rule them all
As I was coding the proof of concept, I realized that I had missed a crucial fact that would make the attack inviable in this particular endpoint.
Because of the way the attack works, several requests had to be made to the /p/chromium/issues/entryafterlogin endpoint until I would be able to leak the full token.
But there was a problem: after each request, a completely new token was generated, which in turn would change the location the page was going to be redirected to, preventing the attack from working.
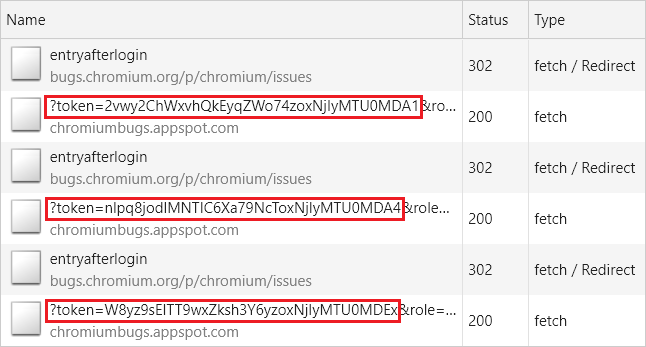
Fortunately, upon closer inspection, because the Cache-Control header was set to “private”, I realized I could execute a fetch with the “force-cache” option set and cache the endpoint’s response (including the Location header containing the URL with the CSRF token).
fetch("https://bugs.chromium.org/p/chromium/issues/entryafterlogin", {
mode: "no-cors",
credentials: "include",
cache: "force-cache"
});
Through that I could ensure that subsequent requests wouldn’t load from the network, but would instead come from the cache (effectively freezing the URL of the redirect and consequently the CSRF token), allowing the attack the be performed.
Wrapping it up
With no more obstacles in the way, I finished the code for the proof of concept (the entire exploit can be found on https://gist.github.com/lbherrera/6e549dcf49334b637c22d76518a90ff6).
But the story didn’t end here…
Almost one year later, I revised the attack and noticed that it was still possible to pull it off through an alternative way - which in hindsight was obvious.

Due to a flaw in the AppCache specification (highlighted above), it was possible to perform the attack again by abusing the way URLs were matched (by prefix).
If a cache manifest like the one below was registered, requests made to URLs starting with the “https://facebook.com/v" prefix would be allowlisted and return successfully, while requests that didn’t start with that prefix would be rejected and blocked.
CACHE MANIFEST
NETWORK:
https://facebook.com/me
https://facebook.com/v
This meant that under the rules of the cache manifest above, requests to the following URLs would all work:
- https://facebook.com/v
- https://facebook.com/vi
- https://facebook.com/vic
- https://facebook.com/vict
- https://facebook.com/victi
- https://facebook.com/victim
And that a request to “https://facebook.com/anothervictim" wouldn’t - precisely the behavior that enabled the attack to happen last time.
This warranted another report to the Chrome VRP!
After I realized this was an issue in the specification, I tested other browsers and learned that although Firefox was once vulnerable, they were already far into the deprecation process of AppCache and had disabled it by default in their stable version (and to re-activate it, users would have to enable a flag).
For those wondering - this adventure and the two bugs combined (CVE-2020-6399 and CVE-2021-21168) resulted in a bounty of $10000 dollars :)
Thanks for reading!